

For most of us, including me, most of my interaction with AI has been through chatbots. The ability to text your AI assistant about anything, at any time of day, and receive a useful and helpful response back has been profound shift in productivity and creativity.
But text chat is only one interface to interact with AI. While we all been typing away, AI’s “multimodal” capabilities have quietly and impressively been improving in the background. AI tools now have eyes and ears that allow them to see, hear, and respond to the world around them. This shift is happening alongside ubiquitous mobile apps (as always, a reminder to go on that AI stroll), and even wearable devices like AI powered glasses.

Have you started seeing (less good looking) Meta glasses wearers like these two pop up in the real world? I have, and honestly, I’m tempted. The path to integrating AI into “real world” uses will only improve, though not without some privacy concerns. Meta’s commercial success shows this format is here to stay: from 300K first-gen sales to over 2M second-gen units, with plans to reach 10M by the end of 2026. There are also other, exciting new AI device efforts on the near horizon.
It’s coming for work, too. Multimodal assistants can now see your screen, understand your context, and have a live, back-and-forth conversation with you while you share video or present content.
Let’s take a closer look at what’s available and what we can do with them.
The Evolution of Vision AI
Multimodal technology didn’t appear overnight. After AlexNet’s 2012 breakthrough in computer vision, researchers developed models that could both see and describe (image captioning, VQA). Later came the Transformer and Vision Transformer, contrastive training (CLIP), and diffusion models for text-to-image. Whisper made speech recognition robust.
By 2023, GPT-4 and ChatGPT could see, hear, and speak. Google’s Gemini launched multimodal from day one. Anthropic’s Claude 3/3.5 improved visual reasoning. In 2024, GPT-4o made multimodality real-time. And in 2025, Microsoft’s Copilot Vision brought these capabilities into Edge and the Copilot app—so your AI can literally look at your screen or through your camera and help live.
It’s only going to become more available and integrated from here.
The AI vision vision
In the last few weeks, I’ve been using a new tool that my employer rolled out for personal M365 and windows users called “Copilot Vision” that feels like a glimpse into our AI future. To understand Microsoft’s prediction of where this is all going, this video below is useful.

What jumped out at me (other than this guy’s fantastic hair) is in the first minute
“The world of, sort of, mousing around, and keyboarding around, and typing, will feel as alien, as it does to Gen Z to sort of...use DOS.”
Bold words, but it’s not just David. You can sense this direction in Meta’s and OpenAI’s demos: Zuck braiding his daughter’s hair with Meta glasses guidance, or OpenAI employees learning pour-over coffee via the mobile app. All point toward a future where AI integrates seamlessly through voice and vision.
If you squint, they’re all pointing towards the same (near-term) future – one where we incorporate AI into our life seamlessly through voice with our devices. (Yet again, 2002’s Minority Report technology continues to hold up!)
Meet the Multimodal Tools
For the purposes of this post, I’m going to focus on capabilities from the “Big 3” LLM services, along with Copilot (which is built by Microsoft using OpenAI models). A quick overview of what multimodal features area available from those services today below:

Let’s try them out!
Laptop use (through Copilot Vision)

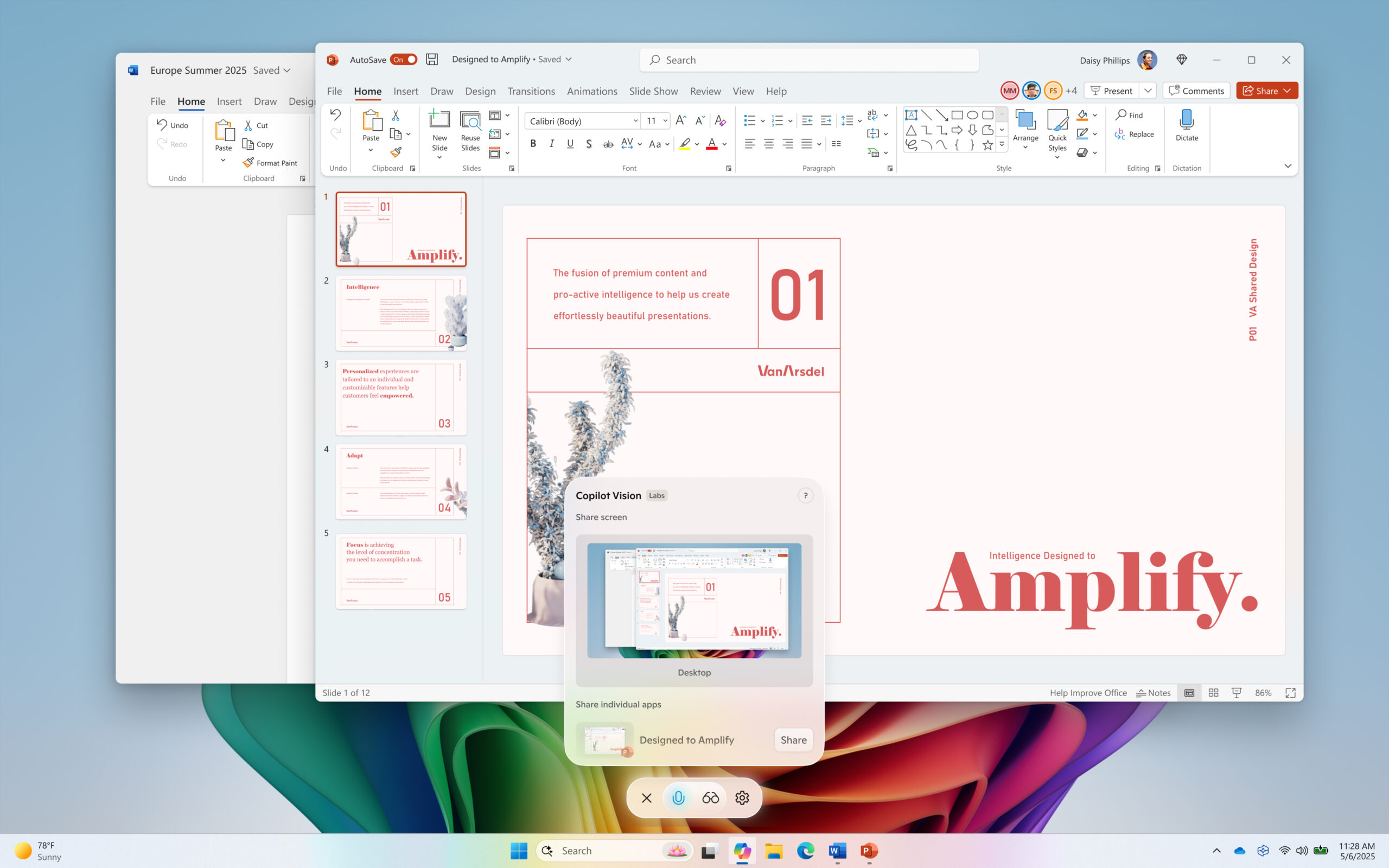{kind=link}
This handy new feature from Microsoft allows you to interact with AI while surfing the web or doing anything that could be captured in an Edge browser or in Windows. It’s an AI collaborator that you can talk to while you use your laptop and it’s the only offer (that I know of at least) that isn’t tied to a mobile app. Anyone with just a Microsoft account should be able to use it.
What you’ll need: Windows 11 Copilot App and/or Microsoft Edge Web Browser (Right now this is a feature available to personal users on their personal devices (though I’m sure it’ll be rolled out to enterprise users and Office very soon).
How it works: Bring up Copilot (either Windows app or in Edge browser, like the picture below), click the Microsoft “Talk to Copilot” button, and start your conversation.

These capabilities are changing constantly, but at least for right now, a couple things to know:
Copilot Vision can only view what’s on your direct screen. It can pull in information and respond to queries just like any other AI service though. But it’s not going to scroll through a 50-page pdf and summarize it like general Copilot can, it’s more for immediate current work.
The Windows 11 Copilot App can only share one working application at a time, not your entire screen. At least for right now, you choose which app you want it to assist you with, and it can be anything in Windows (not just Microsoft products) – see picture below.

To give you a better sense of it, here’s a little video of me using it in action:
Already available for Windows and Edge browsers, expect these capabilities to expand throughout the entire Microsoft software suite. Where there’s Copilot today, there will likely be Copilot Vision available soon.
AI Mobile Apps (the Big 3)
The most common multi-modal tool is the ability to work with your favorite AI via its mobile app (especially ChatGPT and Gemini). AI with eyes and ears have now been integrated into our mobile devices with impressive capabilities that aren’t (yet) available on their laptop web versions.
What you’ll need: Subscription to one of the Big 3 AI Services for all the tools, along with their respective IOS or Android mobile app.
How it works: Bring up the mobile app and use the voice feature to start your conversation. With GPT and Gemini, you can share video feed and screenshare. (Claude doesn’t have video feed option but can upload pictures and work on files together.)
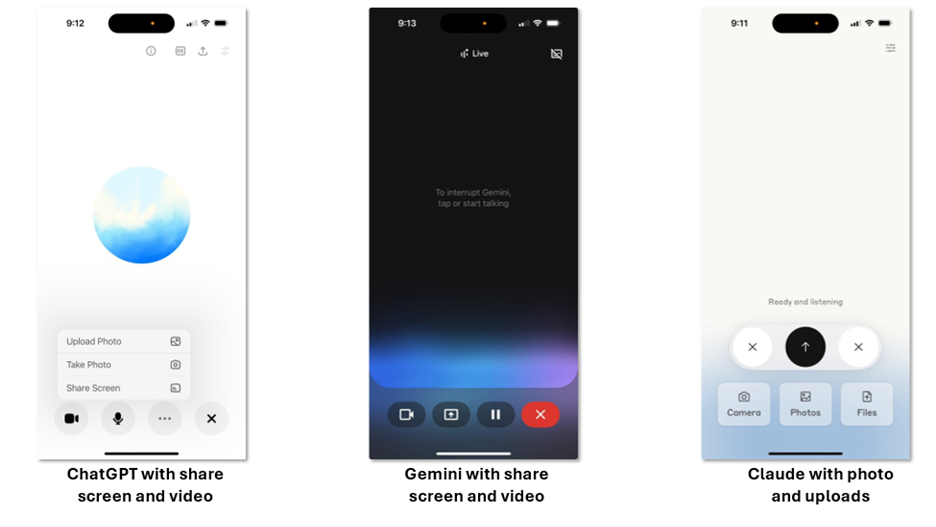
What might you use this for? A few ideas:
Pantry: Show a video of your pantry and ask it something like: “Here are the ingredients I have—give me a 25-minute, high-protein family dinner with steps a kid can help with.”
Nature ID for kids: Video a plant and ask it: “What is this bug/plant? Explain for a 4-year-old in 2 sentences and ask him one fun question about it.”
Translate on the fly (menus, signs, forms): “Translate this menu to English and highlight vegetarian dishes.”
Home/DIY troubleshooting: Try using video around the house, asking things like “What’s plugged in wrong here? Walk me through fixing this step-by-step.” or “Identify this cable and tell me which port it goes in.”
Travel navigation: show it a map of your metro/bus schedule/etc. and ask it for real instructions on how you want to get where you need to.
Just about anything else you can think of…
Just give it a try
My main suggestion is to experiment with the AI mobile app’s voice and video features that are available to you today. And even if you’re not an Edge user, download it for free and give Copilot Vision a try. The desktop app is especially handy for work tasks like Excel formulas, writing feedback, or quick research without breaking focus.
We’re standing at the edge of a pretty wild shift. In just a couple of years, “talking to your AI” won’t just mean typing into a box—it’ll mean pointing at things, showing it what you see, and having it help in real time, wherever you are. Whether it’s glasses, your phone, or your laptop, the line between “using a tool” and “working with a partner” is about to blur. So go ahead—put AI’s new eyes and ears to work.
You might be surprised at how quickly it starts feeling less like science fiction and more like any other tool you reach for.
